分组聚合不再难:Pandas groupby使用指南
处理大量数据时,经常需要对数据进行分组和汇总,groupby为我们提供了一种简洁、高效的方式来实现这些操作,从而简化了数据分析的流程。
1. 分组聚合是什么
分组是指根据一个或多个列的值将数据分成多个组,每个组包含具有相同键值(这里的键值即用来分组的列值)的数据行。
聚合或者汇总则是指,在分组后,可以对每个组应用聚合函数(如求和、平均值、计数等),从而得到每个组的汇总信息。
2. 准备数据
下面的示例中使用的数据采集自A股2024年1月和2月的真实交易数据。
数据下载地址:https://databook.top/。
导入数据:
import pandas as pd
fp = r'D:\data\2024\历史行情数据-不复权-2024.csv'
df = pd.read_csv(fp)
df = df.loc[:, ["股票代码", "日期", "开盘", "收盘", "最高", "最低", "成交量"]]
df

3. groupby 使用示例
下面通过具体的示例演示groupby常用的使用方法。
3.1. 单列分组再聚合
单列聚合是指针对某一列汇总计算,比如:
针对“股票代码”聚合,看看不同股票的开盘价和收盘价的平均值。
# 只保留需要的列
data = df.loc[:, ["股票代码", "开盘", "收盘"]]
# 根据股票代码聚合平均值
data.groupby(by=["股票代码"]).mean()
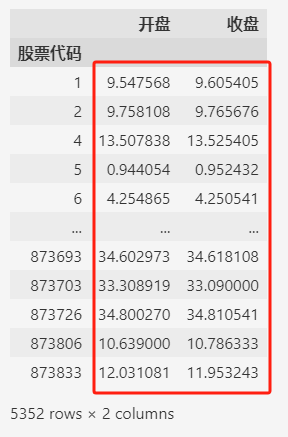
一共5352支股票,聚合之后,红色框内的是每支股票开盘价和收盘价的平均值。
3.2. 多列分组再聚合
多列分组聚合时,按照groupby中by参数的顺序,依次进行分组,然后再聚合。
本次的使用的数据包含2024年1月和2月的数据,
我们先按照“股票代码”分组,再按“月份”分组,最后汇总信息。
聚合之前,先把日期的格式转换成月的形式:
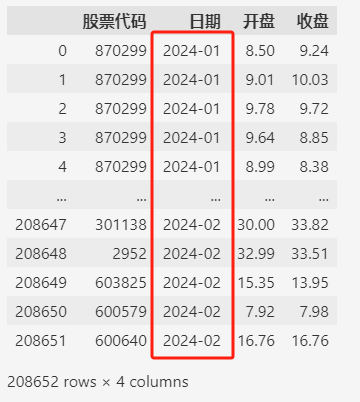
data = df.loc[:, ["股票代码", "日期", "开盘", "收盘"]]
data["日期"] = data["日期"].str.slice(0, 7)
data
根据“股票代码”和“日期”来聚合每支股票每个月的开盘价和收盘价的最大值:
data.groupby(by=["股票代码", "日期"]).max()

聚合之后的DataFrame,有2个Index(索引)。
3.3. 一次分组多次聚合
聚合汇总信息时,可以一次汇总多个信息,这样分组一次就可以了,不用每次聚合都重复调用groupby去分组。
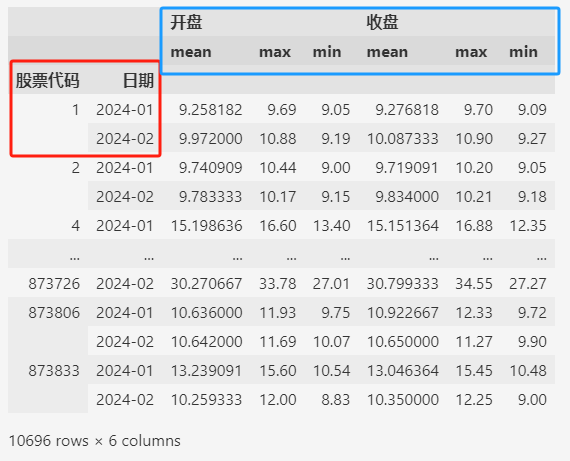
比如,下面的示例一次汇总出每支股票每个月开盘价和收盘价的最大值,最小值,平均值:
data.groupby(by=["股票代码", "日期"]).agg(["mean", "max", "min"])
3.4. 定制分组的聚合方式
更进一步,我们还可以针对不同的列采用不同的聚合方式。
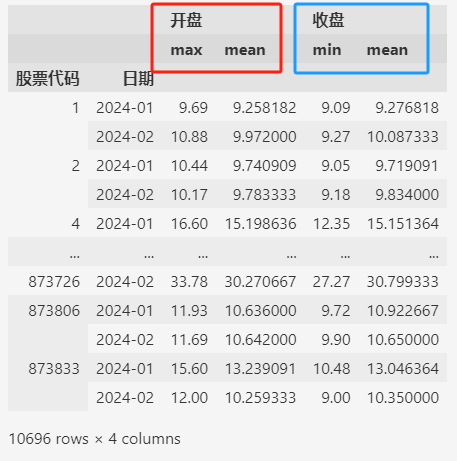
比如,对开盘价汇总最大值和平均值,对收盘价汇总最小值和平均值:
data.groupby(by=["股票代码", "日期"]).agg(
{
"开盘": ["max", "mean"],
"收盘": ["min", "mean"],
}
)
3.5. 聚合后重置索引
从上面聚合后数据的截图中,可以发现,聚合之后,分组用的列(比如 ["股票代码", "日期"])变为索引。
如上所示,聚合之后返回的DataFrame,红色框内的是索引(index),蓝色框内的是列(columns)。
如果,我们希望分组聚合统计之后,分组的列(比如 ["股票代码", "日期"])仍然作为DataFrame的列,
可以在groupby分组时使用as_index=False参数。
data.groupby(by=["股票代码", "日期"], as_index=False).agg(
{
"开盘": ["max", "mean"],
"收盘": ["min", "mean"],
}
)
这样的话,分组的列(比如 ["股票代码", "日期"])就不会成为索引。
4. 总结
总的来说,groupby 函数是 pandas 库中一个非常常用的工具,它大大简化了数据处理和分析的过程,
使得用户能够更高效地洞察和理解数据。
热门相关:神医嫁到 混在三国当军阀 貌似纯洁 士子风流 名门贵妻:暴君小心点