redis-cli创建Redis集群时显式指定主从节点
背景
前些年用python写过一个Redis Cluster 自动化安装,扩容和缩容的工具,虽然当时官方的的redis-trib.rb集群创建工具提供了集群创建、 检查、 修复、均衡等命令行功能,个人接受不了redis-trib.rb,原因在于redis-trib.rb需要ruby的环境,同时无法自定义指定集群中节点的主从关系。随后Redis 5.0版本中将集群的创建集成到Redis-cli中,免去了ruby环境的依赖,但是在创建集群的时候,同样无法直接指定主从节点,如何自定义实现集群中节点的主从关系问题,强迫症要求笔者必须尝试如何指定具体的主从节点。
以下使用单机多实例的方式做测试验证,本地启用8个Redis实例,端口号分别是9001~9008
redis-cli --cluster创建集群时无法明确直接指定主从节点
redis-cli --cluster create命令在给定的Redis实例中,如果指定了 --cluster-replicas ,会根据实例个数,用半数节点做创建集群的主节点,半数节点做集群节点的从节点。
如果命令直接指定6个实例,端口号从9001~9006
redis-cli --cluster create 172.22.13.50:9001 172.22.13.50:9002 172.22.13.50:9003 172.22.13.50:9004 172.22.13.50:9005 172.22.13.50:9006 --cluster-replicas 1 -a ******
预期的是9004作为9001的从节点,9005作为9002的从节点,9006作为9003的从节点,但是默认的分配如下,9005作为9001的从节点,9006作为9002的从节点,9004作为9003的从节点。

参考网上一些用单独6个实例做cluster时,在命令行的节点中,他的分配规则都是用第五个节点作为第一个节点的从节点,第6个节点作为第二个节点的从节点,第四个节点作为第三个节点的从节点

上图参考:https://www.servermania.com/kb/articles/how-to-setup-and-scale-a-redis-cluster
通过调整--cluster create后面节点的顺序来生成主从
根据其分配规律,调整--cluster create后面的实力的顺序,把9006放在第四个位置,然后是9004和9005节点,这次他就按照预期的(9004作为9001的从节点,9005作为9002的从节点,9006作为9003的从节点)的方式分配了。
redis-cli --cluster create 172.22.13.50:9001 172.22.13.50:9002 172.22.13.50:9003 172.22.13.50:9006 172.22.13.50:9004 172.22.13.50:9005 --cluster-replicas 1 -a redis@password110
通过--cluster add-node来显式为主节点增加从节点
根据默认情况下cluster create生成主从的规律,上述方式通过调整--cluster create后面节点的顺序来生成主从,能够按照预期分配主从节点,但笔者并没有能力去调试或者修改Redis的源码,cluster create创建集群仍旧是一个黑盒,所以上述方式并不一定是可以完全自控。下面尝试通过--cluster add-node来显式为主节点增加从节点。
#1创建三节点的集群,不指定从节点
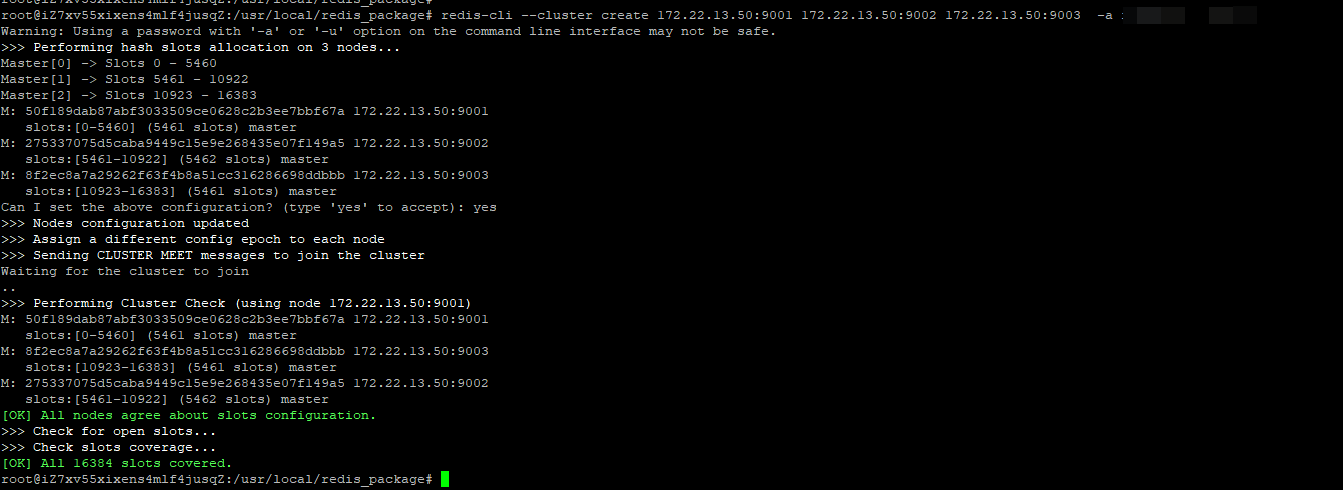
#2检查集群状态以及节点的id

#3添加从节点

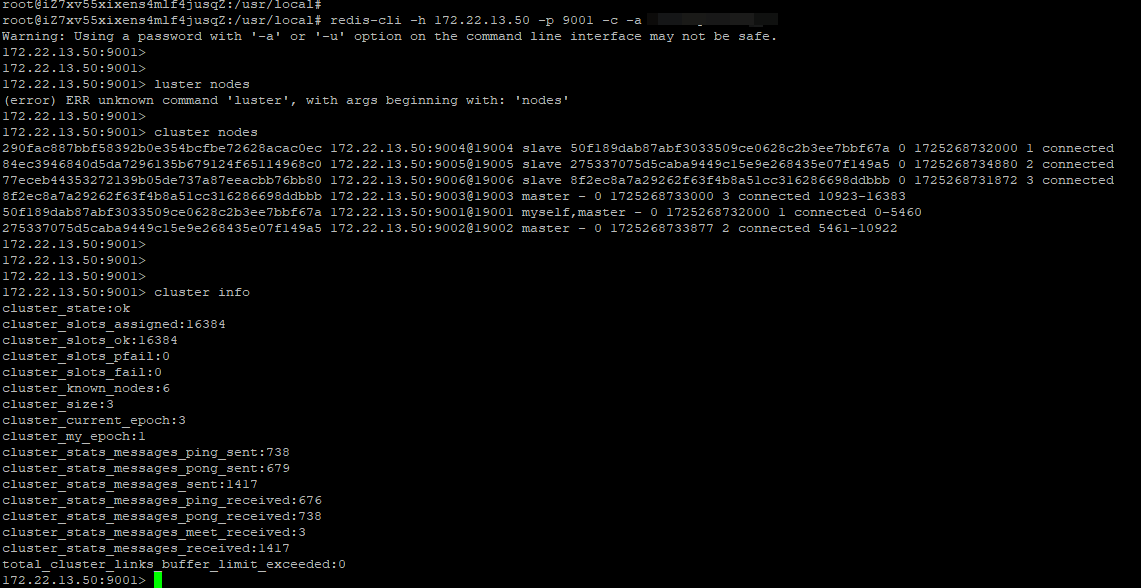
#4集群检查
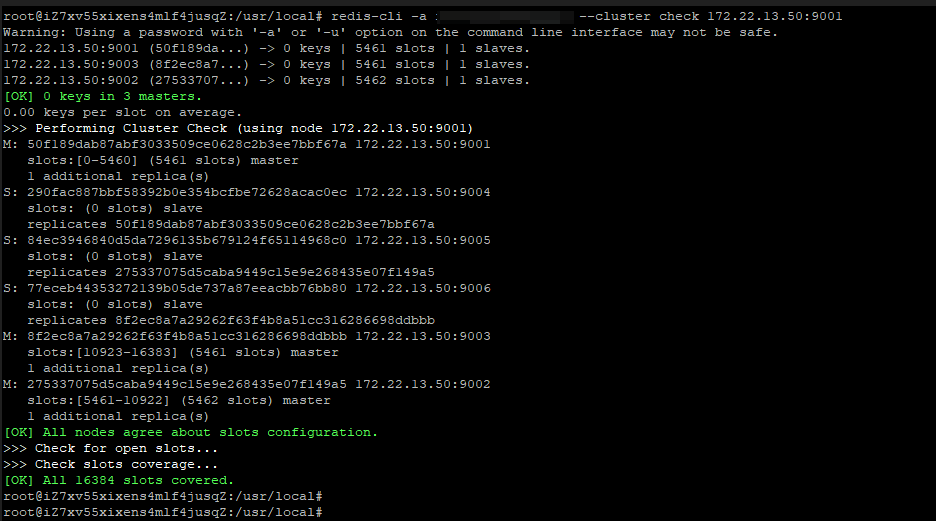
#5集群修复
redis-cli -a ****** --cluster fix 172.22.13.50:9001 (连接至任意一个节点用fix命令)
#6集群扩容
#1添加主节点,新节点在前,已有节点在后(这个节点可以是集群中的任意一个节点)
这里将172.22.13.50:9007节点加入到集群中,默认最为主节点

#2新节点加入后reshard,(连接至任意一个节点用check命令)
redis-cli --cluster reshard -a ****** 172.22.13.50:9001
reshard需要指定分配多少个slot给新节点,这些节点来自于哪些节点,这里分配4000个slot给新节点,从所有已有的节点中平均分配
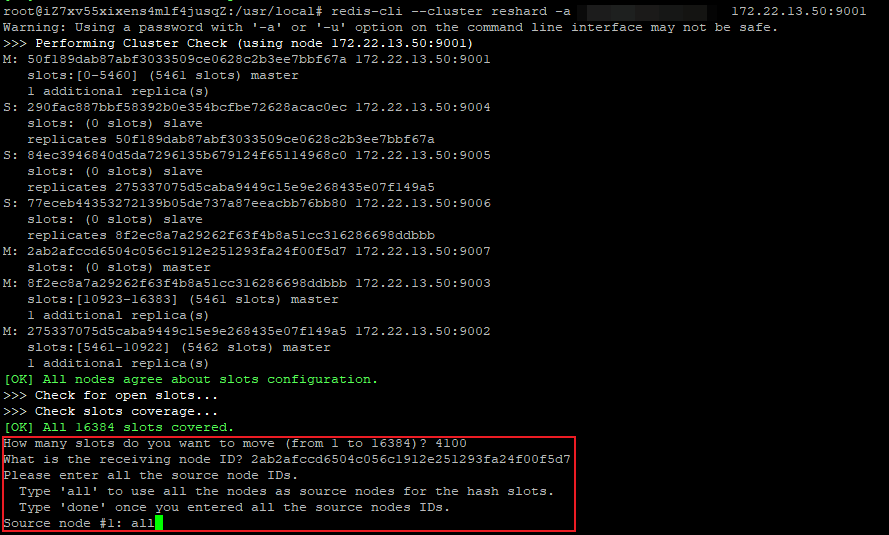

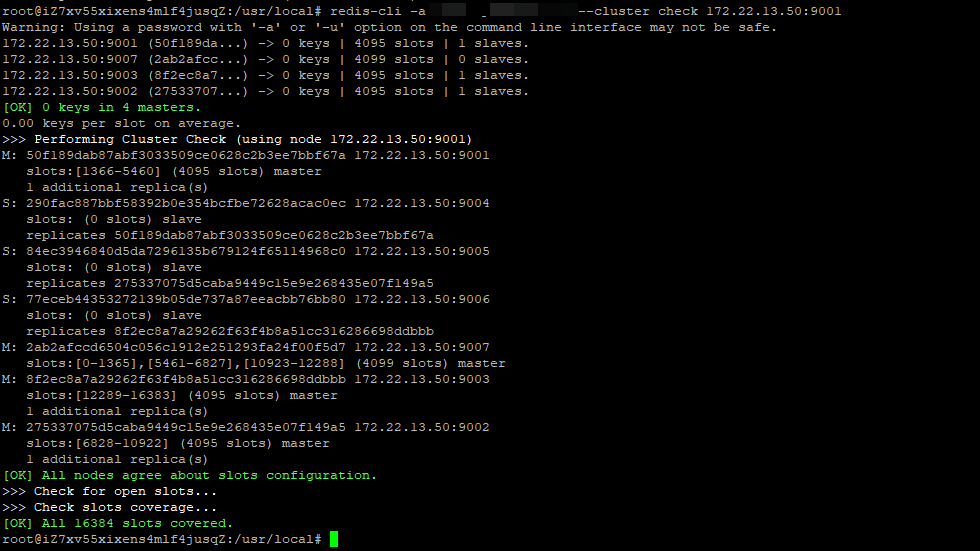
#3reshared后给新增加的主节点添加从节点。新节点在前,已有节点在后

相关命令
###直接指定所有节点,让redis-cli分配主从 redis-cli --cluster create 172.22.13.50:9001 172.22.13.50:9002 172.22.13.50:9003 172.22.13.50:9004 172.22.13.50:9005 172.22.13.50:9006 --cluster-replicas 1 -a redis@password ###仅指定集群中的主节点 redis-cli --cluster create 172.22.13.50:9001 172.22.13.50:9002 172.22.13.50:9003 -a redis@password ###检查集群状态以及节点的id redis-cli -h 172.22.13.50 -p 9001 -c -a redis@password cluster nodes 172.22.13.50:9001> cluster nodes 974e681f32f112409e89ae175cf3edb12702c11d 172.22.13.50:9002@19002 master - 0 1725259430884 2 connected 5461-10922 f473fe68970a278f9603c38514fdf4fe1ec138f4 172.22.13.50:9003@19003 master - 0 1725259429881 3 connected 10923-16383 7b55dcc9bab206193a3d2eb27235f450388b3689 172.22.13.50:9001@19001 myself,master - 0 1725259428000 1 connected 0-5460 ###添加从节点,新节点在前,已有节点在后 语法: redis-cli --cluster add-node new_host:new_port existing_host:existing_port --cluster-slave --cluster-master-id <arg> redis-cli --cluster add-node -a redis@password 172.22.13.50:9004 172.22.13.50:9001 --cluster-slave --cluster-master-id 3eae6e526ee8bfbc88794007a25f70447b2da045 redis-cli --cluster add-node -a redis@password 172.22.13.50:9005 172.22.13.50:9002 --cluster-slave --cluster-master-id 78735239b0f8da1ce9b5599c02bd04fca38cdd3a redis-cli --cluster add-node -a redis@password 172.22.13.50:9006 172.22.13.50:9003 --cluster-slave --cluster-master-id 51d326f4d525b4bb9dc2bb352919fcdd6a3e54b8 ###添加主节点,新节点在前,已有节点在后 redis-cli --cluster add-node -a redis@password 172.22.13.50:9007 172.22.13.50:9001 ###新节点加入后reshared,扩容直接连接到集群的任意一节点 redis-cli --cluster reshard -a redis@password 172.22.13.50:9001 ###reshared后给新增加的主节点添加从节点。新节点在前,已有节点在后 redis-cli --cluster add-node -a redis@password 172.22.13.50:9008 172.22.13.50:9007 --cluster-slave --cluster-master-id 59b109b5e6dfea6fad5e75c2a95983c7024ca48c ###集群检查 redis-cli -a redis@password --cluster check 172.22.13.50:9001 ###集群修复 redis-cli -a redis@password --cluster fix 172.22.13.50:9001
Redis Cluster configuration parameters
参考https://redis.io/docs/latest/operate/oss_and_stack/management/scaling/
We are about to create an example cluster deployment. Before we continue, let's introduce the configuration parameters that Redis Cluster introduces in the redis.conf file.
- cluster-enabled
<yes/no>: If yes, enables Redis Cluster support in a specific Redis instance. Otherwise the instance starts as a standalone instance as usual. - cluster-config-file
<filename>: Note that despite the name of this option, this is not a user editable configuration file, but the file where a Redis Cluster node automatically persists the cluster configuration (the state, basically) every time there is a change, in order to be able to re-read it at startup. The file lists things like the other nodes in the cluster, their state, persistent variables, and so forth. Often this file is rewritten and flushed on disk as a result of some message reception. - cluster-node-timeout
<milliseconds>: The maximum amount of time a Redis Cluster node can be unavailable, without it being considered as failing. If a master node is not reachable for more than the specified amount of time, it will be failed over by its replicas. This parameter controls other important things in Redis Cluster. Notably, every node that can't reach the majority of master nodes for the specified amount of time, will stop accepting queries. - cluster-slave-validity-factor
<factor>: If set to zero, a replica will always consider itself valid, and will therefore always try to failover a master, regardless of the amount of time the link between the master and the replica remained disconnected. If the value is positive, a maximum disconnection time is calculated as the node timeout value multiplied by the factor provided with this option, and if the node is a replica, it will not try to start a failover if the master link was disconnected for more than the specified amount of time. For example, if the node timeout is set to 5 seconds and the validity factor is set to 10, a replica disconnected from the master for more than 50 seconds will not try to failover its master. Note that any value different than zero may result in Redis Cluster being unavailable after a master failure if there is no replica that is able to failover it. In that case the cluster will return to being available only when the original master rejoins the cluster. - cluster-migration-barrier
<count>: Minimum number of replicas a master will remain connected with, for another replica to migrate to a master which is no longer covered by any replica. See the appropriate section about replica migration in this tutorial for more information. - cluster-require-full-coverage
<yes/no>: If this is set to yes, as it is by default, the cluster stops accepting writes if some percentage of the key space is not covered by any node. If the option is set to no, the cluster will still serve queries even if only requests about a subset of keys can be processed. - cluster-allow-reads-when-down
<yes/no>: If this is set to no, as it is by default, a node in a Redis Cluster will stop serving all traffic when the cluster is marked as failed, either when a node can't reach a quorum of masters or when full coverage is not met. This prevents reading potentially inconsistent data from a node that is unaware of changes in the cluster. This option can be set to yes to allow reads from a node during the fail state, which is useful for applications that want to prioritize read availability but still want to prevent inconsistent writes. It can also be used for when using Redis Cluster with only one or two shards, as it allows the nodes to continue serving writes when a master fails but automatic failover is impossible.