记一次基于倒序索引的SQL优化
本文测试环境为SQLserver2019
背景
create table TestTable01 ( id bigint identity, --主键Id,自增 business_code char(7), --业务编码,一定范围内(测试代码从BC00001~BC00200) business_timestamp datetime2, --业务发生时间戳 business_value decimal(15,3), --业务发生时涉及的数值 business_status tinyint, --业务状态编码(测试数据范围为1~5) other_col varchar(100), constraint pk_TestTable01 primary key(id) );
基于上述表结构,简化数据量,基于时间顺序生成1千万条数据
declare @i int = 0 begin tran while @i<10000000 begin insert into TestTable01 values (concat('BC',FORMAT(cast(rand()*200 as int), '00000')),dateadd(ss,@i,'2024-01-01'),rand()*10000,rand()*5,newid()) set @i = @i+1 end commit
反向索引扫描的执行计划
create index idx_bcode_statue on TestTable01 (business_code,business_status)
select top 30 * from TestTable01 where business_code = 'BC00146' and business_status in (3, 5) order by id desc

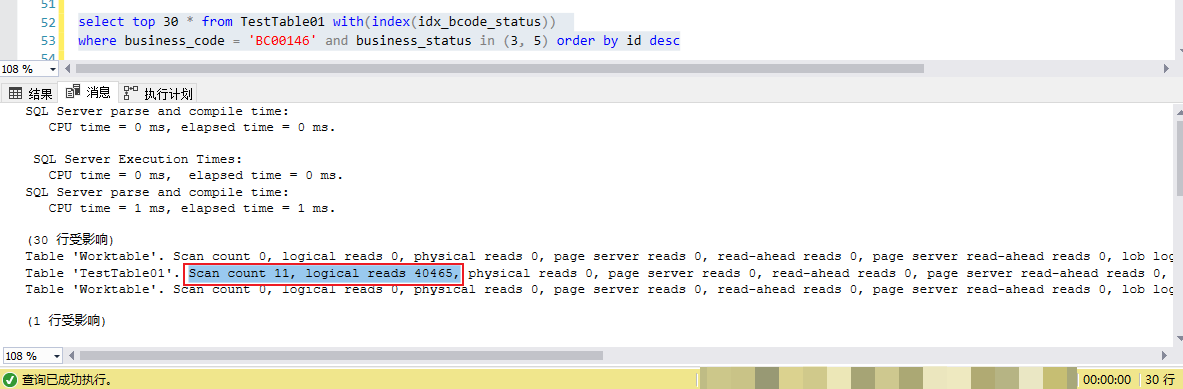
上述查询IO以及CPU消耗信息,342次IO以及几乎为0的CPU消耗,,总耗时6毫秒,这个代价确实不大
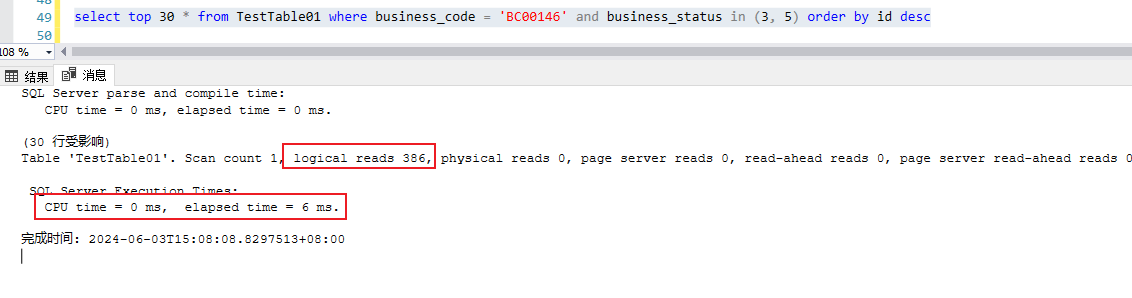

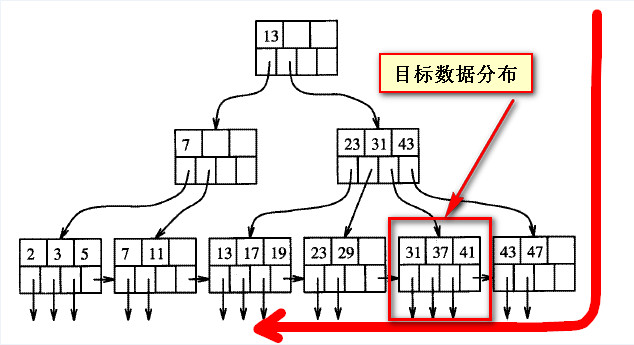
这里不难理解,对于“聚集索引”这个B+树,因为是查询某个业务代码的某两种状态最新的30条数据,安装数据的生成逻辑(主键值跟随时间戳做递增),所以倒序扫描,绝大多数情况下可以很快找到符合条件的数据。原理如下示意图。所谓的反向索引扫描,就是从B+树的右边开始往左边扫描数据页,直至找到满足查询条件的数据。
可以看到使用了idx_bcode_statue 索引的情况下,执行计划看起来确实是索引查找(index seek),但是相比默认的聚集索引反向扫描,这里的IO代价也翻了数十倍。
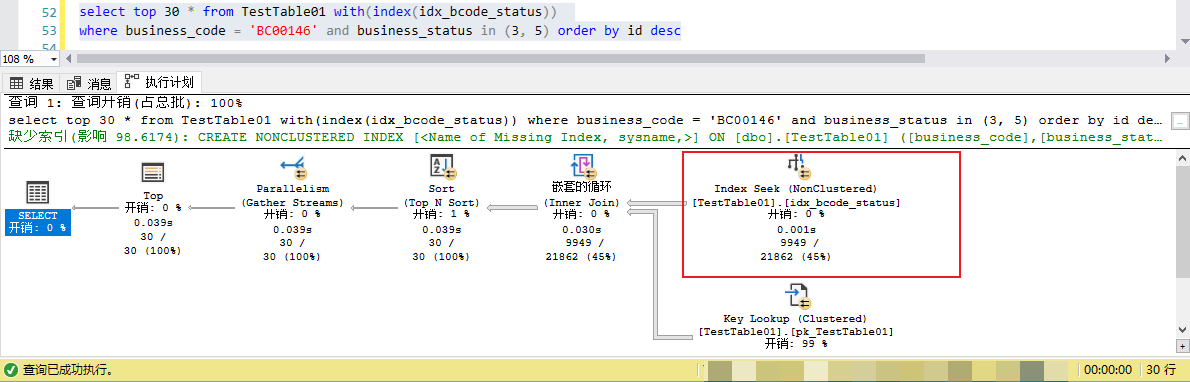
反向索引扫描造成的IO消耗

由上可见:
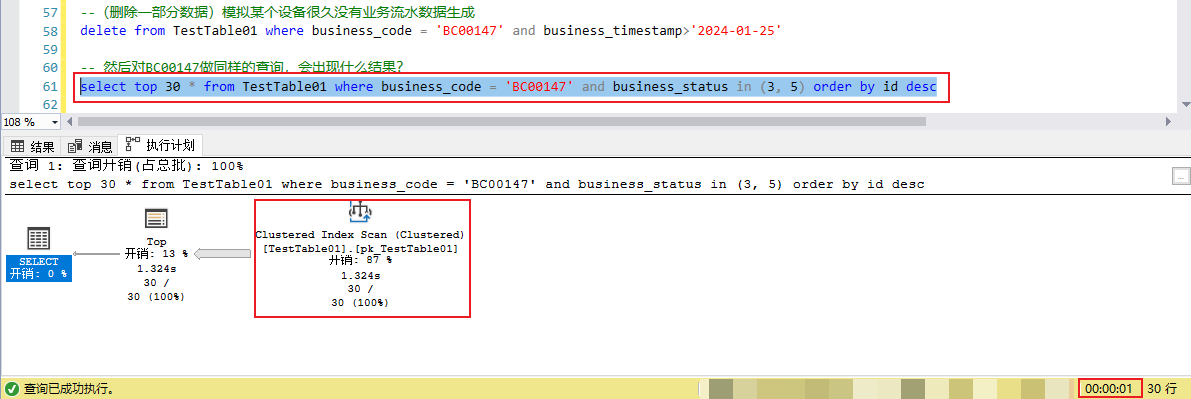
1,基于主键(聚集索引)的反向索引扫描,对于多数case没有问题,但是对于特殊case会造成巨大的IO消耗,并不是一个最优解。
2,对于常规的基于where条件的索引,优化器压根就不会选择它。
如何建立索引
上文一开始就提到了,对于常规的case,优化器默认的反向聚集索引扫描已经是一个最优解了,基于where条件建立的索引(create index idx_bcode_statue on TestTable01 (business_code,business_status)),默认情况下也用不上。但是对于非常规的case,比如上述BC147这种,某些业务代码最近一段时间内并没有产生业务数据,再用默认的反向聚集索引扫描就不合理了,因为这个扫描会扫描出来一大批数据页面,才能找到满足条件的数据,因此这是一个不合理的执行计划。但同时,代码层面无法判断某个业务代码在近期否产生了业务数据,也就无从得知那个参数使用默认的聚集索引扫描更高效。因此需要一种对于两种case都适用的优化方式,既然按照id做倒序排序查询某个业务代码的数据,那可以直接基于业务代码和“倒序”Id的联合索引

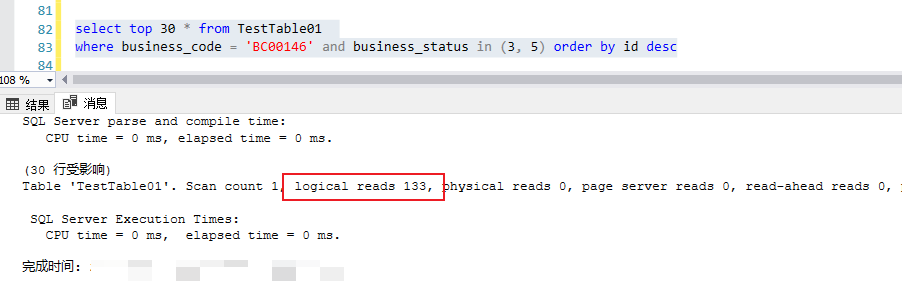
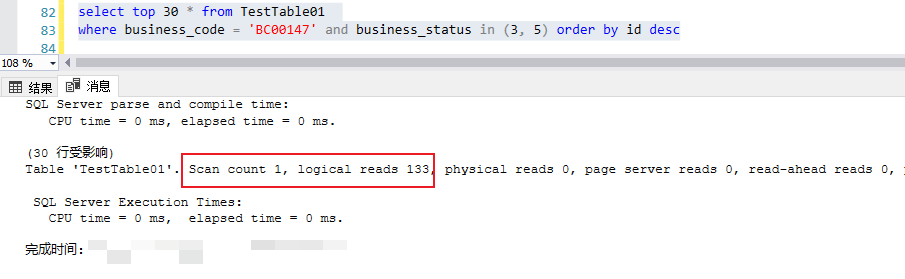
对于基于时间戳最近没有生成数据的case,一样都会基于idx_bcode_id_status 这个索引做index seek

反向索引优化是否适合于MySQL
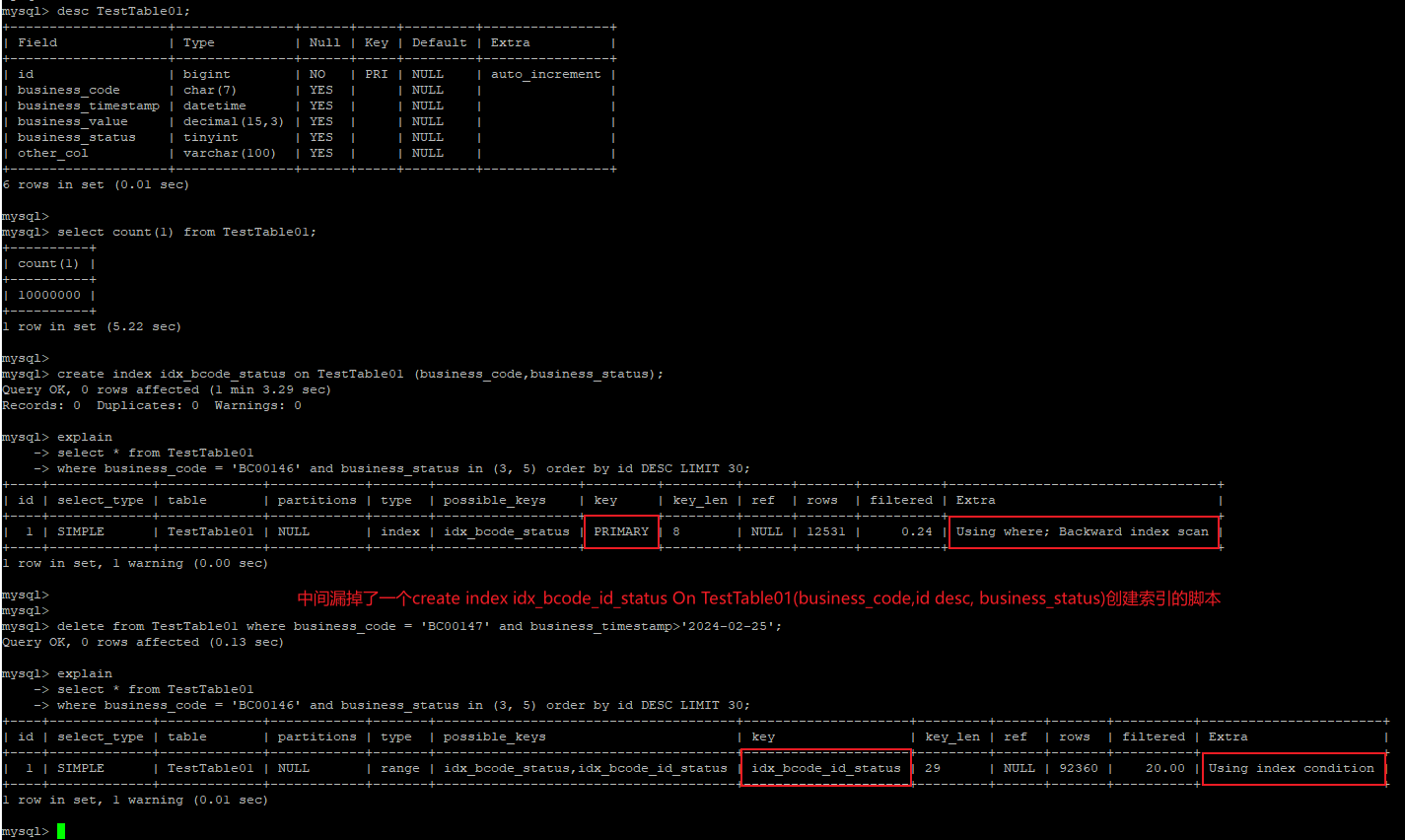
MySQL下测试代码
create table TestTable01 ( id bigint AUTO_INCREMENT NOT NULL PRIMARY key, business_code char(7), business_timestamp datetime, business_value decimal(15,3), business_status tinyint, other_col varchar(100) ); SET GLOBAL innodb_flush_log_at_trx_commit = 0; SET GLOBAL sync_binlog = 0; -- 生成测试数据存储过程 CREATE DEFINER=`root`@`%` PROCEDURE `create_test_data`() LANGUAGE SQL NOT DETERMINISTIC CONTAINS SQL SQL SECURITY DEFINER COMMENT '' BEGIN -- start TRANSACTION; set loop_count = 0; while loop_count<10000000 do INSERT INTO TestTable01(business_code,business_timestamp,business_value,business_status,other_col) VALUES (CONCAT('SC',LPAD(cast(CAST(RAND()*200 AS UNSIGNED int) AS CHAR), 5, '0')),DATE_ADD('2024-01-01', INTERVAL loop_count second),RAND()*10000,CAST(RAND()*5 AS UNSIGNED INT),UUID()); SET loop_count = loop_count + 1; END while; -- COMMIT; END call create_test_data(1000000);
总结
针对查询创建索引的时候,不但要看where条件中字段的选择性,同时要关注排序条件,因为忽略了排序条件的情况下,仅关注查询where的筛选字段,如果直接用索引过滤出来数据,再排序后返回数据,可能是一个非常消耗资源的操作,因此优化器不选择这些索引也很正常,如果能够通过索引建立与查询语句排序一致的索引,才能适应于此类查询。